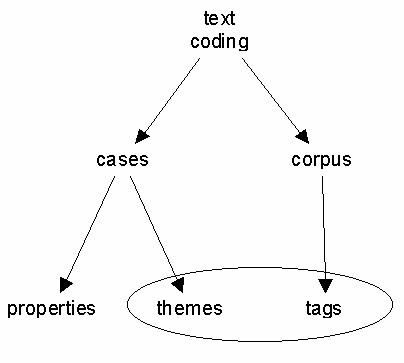
While coding is done both in corpus-based and case-based situations (see text analysis handout), it is easier to discuss coding separately in the two situations. Let's start with case-based coding.
In corpus-based analysis situations, coding usually consists of identifying themes or ideas by labeling them with a short name or number. Let's call this tagging. One reason to do tagging is simply to make it easy to retrieve later. Consider, for example, the following bit of newsmagazine text (on the left):
| TEXT: | CODES: |
| Mixing millennialism, space beliefs and cult charisma can result in a deadly brew, as illustrated by this year’s Heaven’s Gate suicides. Forty people took their lives in the belief that shedding their earthly containers would enable them to board an alien rescue craft headed for the “Next Level” of existence. |
|
The first two codes, <cult> and <suicide> are also words contained in the text. The remaining codes are interpretations of what the paragraph is about. This illustrates both the power and the danger of codes. If we were to rely solely on the presence of key words in text to identify relevant passages, we would often miss important material because an informant can spend quite a bit of time talking about, say, death, without ever mentioning the word. By coding texts, we make sure that we can retrieve all the relevant texts.
The danger, of course, is that our interpretations may be wrong, idiosyncratic, biased, or otherwise not useful. For example, I coded the passage as <transformation> because I saw the idea of committing suicide so as to enter another level of existence as an instance of transformation. However, the author of the passage might not have seen it that way, and another researcher might also not have seen it that way.
Another reason for coding corpus-type data is to facilitate looking for relationships among the ideas in the text. In this sense, coding is a form of data reduction that helps the mind to absorb the corpus. This is the way in which coding is used in grounded theory, semantic network mapping and frame analysis.
In case-based situations, the purpose and style of coding can be exactly the same as in corpus-based situations. More often, however, the purpose is to measure an attribute or property of the underlying case.
For example, think about the annual reports that publicly held companies send to stockholders each year. In particular, let us examine the letter from the CEO which is always included in these reports. For convenience, let's only look at the opening paragraph of each letter (in real life, we would probably look at the whole letter).
Let us suppose that we are interested in the extent to which the corporation is focused on itself rather than the industry. Perhaps we have a theory that when profits are down, the CEO blames the industry, and when profits are up, the CEO credits the company. Hence, we need to code the annual report for two variables: 1) industry vs. self focus in the CEO letter, and 2) profits up or down.
Let us focus on the first variable. There are many ways to code it. One approach is the dictionary method. In this approach, we define a set of words that indicate a focus on, say, industry. So we look for words or phrases like "industry", "the economy", "economic sector", "the market", etc. Then we simply count the number of occurrences of industry-related words. We do the same for the self-focus, and construct some kind of relative index (such as the difference between the frequency of industry words and self referential words).
Another approach is to subjectively rate each CEO letter on, say, a 7 point scale as follows:
| Industry --- | -3 | -2 | -1 | 0 | 1 | 2 | 3 | --- Corporation |
A letter that is completely focused on the industry would receive a score of -3. A letter that divides the attention equally between industry and the corporation would receive a score of 0, and so on.
Here is the opening paragraph for a few such letters (data courtesy of Jang and Barnett), along with my codes:
| Company: | Letter: | Company Focus: |
|---|---|---|
| CATERPILLAR INC | The world's economies continued to struggle in 1992. So did our industry. | -3 |
| EMERSON ELECTRIC CO: | Fiscal 1992 was another record year for Emerson -- our 35th consecutive year of increased earnings and earnings per share, and our 36th consecutive year of increased dividends per share. Sales, earnings, earnings per share and dividends per share all increased at double-digit compound annual growth rates over this period. | 3 |
| FORD MOTOR CO: | Two longtime members of the company's Board of Directors, Dr. Clifton R. Wharton Jr. and former Ford president Philip E. Benton Jr., have left the Board following years of outstanding service to the company. | 3 |
| KOMATSU LTD: | For fiscal 1992 ended March 31, 1992, we have to report rather fragmentary business results, particularly as our key market of construction equipment accommodated shrinking demand, more suddenly than projected at home and continuously abroad. Meanwhile, we are encouraged by the steadfast performance of other operations such as industrial machinery, coupled with affirmative outcomes from our group-wide undertakings in new business areas. Business Results During the year under review, the domestic demand-led Japanese economy began to lose its growth momentum, which was previously fueled by buoyant private-sector capital investment and consumer spending. The slackening economy showed some signs of recession about halfway through the year. Abroad, the recessionary mood continued to prevail over the United States and European economies. | 0 |
| HONDA MOTOR CO LTD: | The fiscal year under review, ended March 31, 1992, was hampered by recessions in the United States and major European countries, as well as by a decelerating Japanese economy. | -2 |
This kind of coding is sometimes referred to as true coding. It is what content analysis is all about. In this kind of coding, we are really measuring attributes of the speaker or case that generated the text. The resulting codes then form an additional variable that is merged with all the other variables that were measured for each case, and then analyzed statistically.
Another type of coding in case-based situations is the identification of themes. Properly speaking, themes could be considered a specific kind of attribute or property, but I have separated them because (a) they are an important subcategory, and (b) they can be identical to what we have called tagging in the context of corpus-based coding. Theme coding is something that is shared by the case and corpus-based approaches.