Density: Ego-centric and Socio-centric
One of the most widely used, and perhaps over-used, concepts in graph theory is that of 'density', which describes the general level of linkage among the points in a graph. A 'complete' graph is one in which all the points are adjacent to one another: each point is
Lines, direction and density 73
connected directly to every other point. Such completion is very rare, even in very small networks, and the concept of density is an attempt to summarize the overall distribution of lines in order to measure how far from this state of completion the graph is. The more points that are connected to one another, the more dense will the graph be.
Density, then, depends upon two other parameters of network structure: these are the 'inclusiveness' of the graph and the sum of the degrees of its points. Inclusiveness refers to the number of points which are included within the Various connected parts of the graph. Put in another way, the inclusiveness of a graph is the total number of points minus the number of isolated points. The most useful measure of inclusiveness for comparing various graphs is the number of connected points expressed as a proportion of the total number of points. Thus, a 20-point graph with five isolated points would have an inclusiveness of 0.75. An isolated point is incident with no lines and so can contribute nothing to the density of the graph. Thus, the more inclusive is the graph, the more dense will it be. Those points which are connected to one another, however, will vary in their degree of connection. Some points will be connected to many other points, while others will be less well connected. The higher the degrees of the points in a graph, the more dense will it be. In order to measure density, then, it is necessary to use a formula which incorporates these two parameters. This involves comparing the actual number of lines which are present in a graph with the total number of lines which would be present if the graph were complete.
The actual number of lines in a graph is a direct reflection of its inclusiveness and the degrees of its points. This may be calculated directly in small graphs, but in larger graphs it must be calculated from the adjacency matrix. The number of lines in any graph is equal to half the sum of the degrees. In Figure 4. 1, as I have already shown, half the sum of the row or column totals is six. The maximum number of lines which could be present in this graph can be easily calculated from the number of points that it contains. Each point may be connected to all except one other point (itself), and so an undirected graph with n points can contain a maximum of n(n-1)12 distinct lines. Calculating n(n-1) would give the total number of pairs of points in the graph, but the number of lines which could connect these points is half this total, as the line connecting the pair A and B is the same as that connecting the pair B and A. Thus, a graph with three points can have a maximum of three lines connecting its points; one with four points can have a maximum of six lines; one with five points can have a maximum of
74 Social network analysis
ten lines; and so on. It can be seen that the number of lines increases at a much faster rate than the number of points. Indeed, this is one of the biggest obstacles to computing measures for large networks. A graph with 250 points, for example, can contain up to 31,125 lines.
The density of a graph is defined as the number of lines in a graph, expressed as a proportion of the maximum possible number of lines. The formula for the density is
![]()
where 1 is the number of lines present. This measure can vary from 0 to 1, the density of a complete graph being 1. The densities of various graphs can be seen in Figure 4.4: each graph contains four points and so could contain a maximum of six lines. It can be seen how the density varies with the inclusiveness and the sum of the degrees.

Figure 4.4 Density comparisons
In directed graphs the calculation of the density must be slightly different. The matrix for directed data is asymmetrical, as a directed line from A to B will not necessarily involve a reciprocated line directed from B to A. For this reason, the maximum number of lines which could be present in a directed graph is equal to the total number of pairs that it contains. This is simply calculated as n(n - 1). The density formula for a directed graph, therefore, is lln(n-1).
Barnes (1974) has contrasted two approaches to social network analysis. On the one hand is the approach of those who seek to
Lines, direction and density 75
anchor social networks around particular points of reference (e.g., Mitchell, 1969) and which, therefore, advocates the investigation of ego-centric' networks. From such a standpoint, the analysis of density would be concerned with the density of links surrounding particular agents. On the other hand, Barnes sees the 'socio-centric' approach, which focuses on the pattern of connections in the network as a whole, as being the distinctive contribution of social network analysis. From this standpoint, the density is that of the overall network, and not simply the 'personal networks' of focal agents. Barnes holds that the socio-centric approach is of central importance as the constraining power of a network on its members is not mediated only through their direct links. It is the concatenation of indirect linkages, through a configuration of relations with properties that exist independently of particular agents, that should be at the centre of attention.
In the case of an ego-centric approach, an important qualification must be made to the way in which density is measured. In an egocentric network it is usual to disregard the focal agent and his or her direct contacts, concentrating only on the links which exist among these contacts. Figure 4.5 shows the consequences of this. Socio-
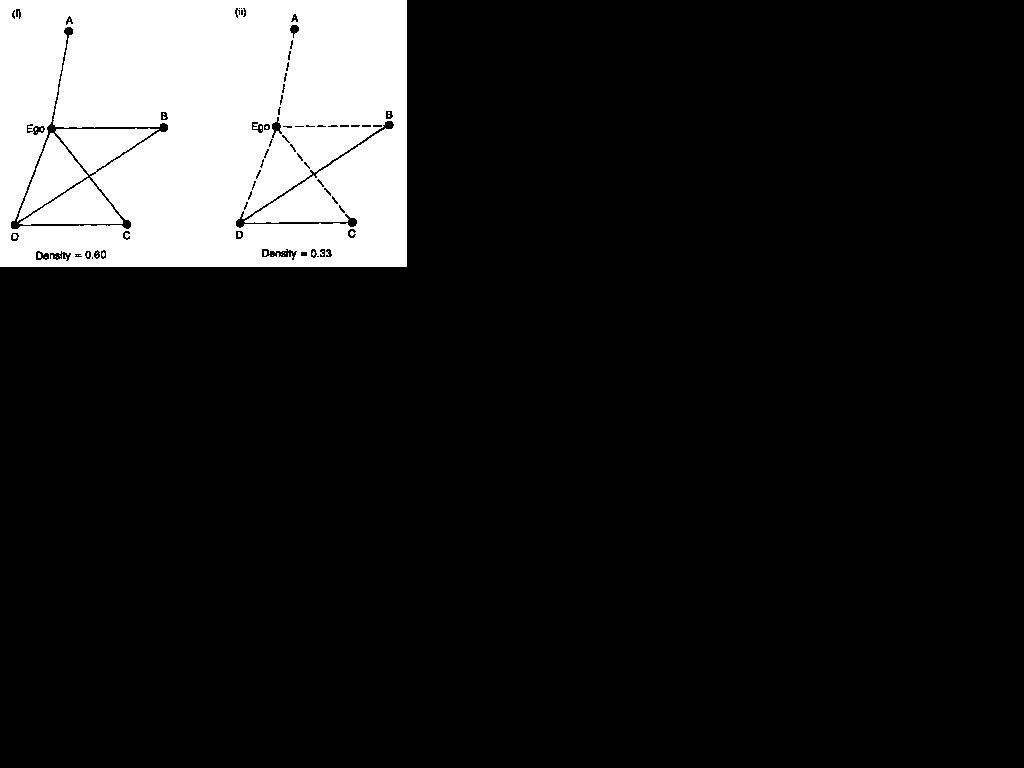
Figure 4.5 Ego-centric measures of density
gram (i) shows a network of five individuals anchored around 'ego'. The sociogram shows ego's direct contacts and the relations which exist among these contacts. There is a total of six lines, and the
76 Social network analysis
density of the sociogram is 0.60. But the density is at this relatively high level principally because of the four lines which connect ego to A, B, C and D. These relations will exist almost by definition, and should usually be ignored. If these data had, for example, been obtained through a questionnaire which asked respondents to name their four best friends, the high density would be an artifact of the question wording. The relations to the four nominated contacts of each respondent will swamp any information about the relations among those who are named by each respondent. The significant fact about sociogram (i) is that there are relatively few connections among ego's own contacts. In sociogram (ii), where ego's direct contacts are shown as dotted lines, there are two relations among A, B, C and D (shown as solid lines), and the four person network has a density of 0.33. It should be clear that this is a more useful measure of the density of the ego-centric network.9
It is also possible to use the density measure with valued graphs, though there is very little agreement about how this should be done. The simplest solution, of course, would be to disregard the values of the lines and to treat the graph as a simple directed or undirected graph. But this involves a considerable loss of information. It might be reasonable, for example, to see lines with a high multiplicity as contributing more to the density of the graph than lines with a low multiplicity. This would suggest that the number of lines in a valued graph might be weighted by their multiplicities: a line with multiplicity 3 might be counted as being the equivalent of three lines. Simple multiplication, then, would give a weighted total for the actual number of lines in a graph. But the denominator of the density formula is not so easy to calculate for valued graphs. The denominator, it will be recalled, is the maximum possible number of lines which a graph could contain. This figure would need to be based on some assumption about the maximum possible value which could be taken by the multiplicity in the network in question. If the maximum multiplicity is assumed to be 4, then the weighted maximum number of lines would be equal to four times the figure that would apply for a similar unvalued graph. But how might a researcher decide on an estimate of what the maximum multiplicity for a particular relation might be? One solution would be to take the highest multiplicity actually found in the network and to use this as the weighting (Barnes, 1969). There is, however, no particular reason why the highest multiplicity actually found should correspond to the theoretically possible maximum. In fact, a maximum value for the multiplicity can be estimated only when the researcher has some independent information about the nature of the relationships under investigation. In the case of company interlocks, for
Lines, direction and density 77
example, average board size and the number of directorships might
be taken as weightings. If the mean board size was five, for example, and it is assumed that no person can hold more than two directorships, then the mean multiplicity would be 5 in a complete and fully connected graph.
In the case of the company sociogram in Figure 3.5, for example, the weighted total of lines measured on this basis would be 5 times 6, or 30. The actual total of weighted lines in the same Sociogram, produced by adding the values of all the lines, is 12, and so the multiplicity-based density would be 12/30, or 0.4. This compares with a density of 1.0 which would be calculated if the data were treated as if they were unvalued. It must be remembered, however, that the multiplicity-based calculation is based on an argument
about the assumed maximum number of directorships that a person can hold. If it were assumed that a person could hold a maximum of three directorships, for example, then the density of the company sociogram would fall from 0.4 to 0.2. For other measures of intensity, there is no obvious way of weighting lines. 10
The density measure for valued graphs, therefore, is highly sensitive to those assumptions which a researcher makes about the data. A measure of density calculated in this way, however, is totally incommensurable with a measure of density for unvalued data. For this reason, it is important that a researcher does not simply use a measure because it is available in a standard r)rolram. A researcher must always be perfectly clear about the ass@ mptions that are involved in any particular procedure, and must report these along with the density measures calculated. The problem in hand-
ling valued data may be even more complex if the values do not refer to multiplicities.
A far more fundamental problem which affects all measures of density must now be considered. This is the problem of the dependence of the density on the size of a graph, which prevents density measures being compared across networks of different sizes (see Niemeijer, 1973; Friedkin, 1981; Snijders, 1981). Densit , it will be recalled, varies with the number of lines which are presenyt in a graph, this being compared with the number of lines which would be present in a complete graph. There are verv good reasons to believe that the maximum number of lines achievable in any real graph may be well below the theoretically possible maximum. If there is an upper limit to the number of relations that each agent can sustain, the total number of lines in the graph will be limited bv the number of agents. This limit on the total number of lines means'that larger graphs will, other things being equal, have lower densities than small graphs. This is linked, in particular, to the time
78 Social network analysis
constraints under which agents operate. Mayhew and Levinger (1976) argue that there are limits on the amount of time that people can invest in making and maintaining relations. The time that can be allocated to any particular relation, they argue, is limited, and it will decline as the number of contacts increases. Agents will, therefore, decide to stop making new relations, new investments of time, when the rewards decline and it becomes too costly. The number of contacts that they can sustain, therefore, declines as the size of the network increases. Time constraints, therefore, produce a limit to the number of contacts and, therefore, to the density of the network. Mayhew and Levinger have used models of random choice to suggest that the maximum value for density that is likely to be found in actual graphs is 0.5.1'
The ability of agents to sustain relations is also limited by the particular kind of relation that is involved. A 'loving' relation, for example, generally involves more emotional commitment than an ,awareness' relation, and it is likely that people can be aware of many more people than they could love. This means that any network of loving relations is likely to have a lower density than any network of awareness relations.
I suggested in Chapter 3 that density was one of the network measures that might reasonably be estimated from sample data. Now that the measurement of density has been more fully discussed, it is possible to look at this suggestion in greater detail. The simplest and most straightforward way to measure the density of a large network from sample data would be to estimate it from the mean degree of the cases included in the sample. With a representative sample of a sufficient size, a measure of the mean degree would be as reliable as any measure of population attributes derived from sample data, though I have suggested in the previous chapter some of the reasons why sample data may fail to reflect the full range of relations. If the estimate was, indeed, felt to be reliable, it can be used to calculate the number of lines in the network. The degree sum - the sum of the degrees of all the points in the graph - is equal to the estimated mean degree multiplied by the total number of cases in the population. Once this sum is calculated, the number of lines is easily calculated as half this figure. As the maximum possible number of lines can always be calculated directly from the total number of points (it is always equal to n(n - 1)/2 in an undirected graph), the density of the graph can be estimated by calculating
![]()
which reduces to (n x mean degree)/n(n-1).
Lines, direction and density 79
Granovetter (1976) has gone further than this and has attempted to provide a method of density estimation that can be used when the researcher is uncertain about the reliability of the initial estimate of the mean degree. In some situations there will be a high reliability to this estimate. With company interlock data, for example, the available directories of company information allow researchers to obtain complete information on the connections of the sample companies to all companies in the population, within the limits of accuracy achieved by the directories. In such circumstances, an estimate of mean degree would be reliable. In studies of acquaintance, on the other hand, such reliability is not normally the case, especially when the population is very large. Granovetter's solution is to reject a single large sample in favour of a number of smaller samples. The graphs of acquaintance in each of the sub-samples (the ,random sub-graphs') can be examined for their densities, and Granovetter shows that an average of the random sub-graph densities results in a reliable estimate of the population network density. Using standard statistical theory, Granovetter has shown that, for a population of 100,000, samples of between 100 and 200 cases will allow reliable estimates to be made. With a sample size of 100, five such samples would be needed; with a sample size of 200, only two samples would be needed. 12 These points have been further explored in field research, which has confirmed the general strategy (Erickson et al., 1981; Erickson and Nosanchuck, 1983).
Density is, then, an easily calculated measure for both undirected and directed graphs, it can be used in both ego-centric and sociocentric studies, and it can reliably be estimated from sample data. It is hardly surprising that it has become one of the commonest measures in social network analysis. I hope that I have suggested, however, some of the limits on its usefulness. It is a problematic measure to use with valued data, it varies with the type of relation and with the size of the graph, and, for this reason, it cannot be used for comparisons across networks which vary significantly in size. Despite these limitations, the measurement of density will, rightly, retain its importance in social network analysis. If it is reported along with such other measures as the inclusiveness and the network size, it can continue to play a powerful role in the comparative study of social networks.
| Next Section | Return to Table of Contents |